[版本]
V0.1 Kenneth Lee 先写一个框架出来
[介绍]
写这篇东西原始目的不是为了介绍怎么写Makefile,而是介绍怎么用“基于目标分层”的方式理解一个工具,写作一个概念,定义一个设计或者部署一套代码。
但我介绍这种“方式”的方法是,写一个“Makefile的写作入门”。所以,本文首先是一个“Makefile入门”,然后才是“基于目标分层的方法介绍”。
不少的Makefile的介绍材料总是上来就开始介绍“依赖”,“规则”,而默认你已经知道为什么你需要“依赖”和“规则”了,很多“热爱学习”的工程师也把这些“依赖”和“规则”事无巨细地记在心里,然后你看着他们学习了很久的Makefile,但一直都搞不清楚他学了些啥,写的Makefile也就仿一下别家的模式,什么真的需要,什么不是真的需要,他们是搞不清楚的。
[关于程序编译]
Makefile解决的是编译的问题。编译有什么问题呢?比如说,你有3个C文件——等等,让我们先偏个题,说明一下——Makefile最初是用来解决C语言的编译问题的,所以和C的关系特别密切,但并不是说Makefile只能用来解决C的编译问题。你用来处理Java一点问题没有,但对于Java,显然ant比Makefile处理得更好。但那是细节,你理解了Makefile,理解ant就没有什么难度了。再说了,Makefile本身的格式也不是什么标准,不同的make工具对Makefile本身怎么写细节是不一样的,本文介绍的是这个工具的思想原理,细节你要自己看对应的手册。由于本文是在Linux上写的,所以我会用gnumake的格式作为例子,但从原理上说,它们是非常相似的。
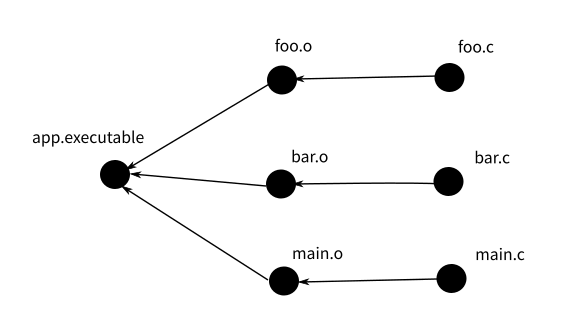
回到“有三个C文件”的问题。比如说,你有foo.c, bar.c, main.c三个C文件,你要编译成一个app.executable,你会怎么做呢?你会执行这样的命令:
gcc -Wall -c foo.c -o foo.o
gcc -Wall -c bar.c -o bar.o
gcc -Wall -c main.c -o main.o
gcc main.o foo.o bar.o -lpthread -o app.executable按Unix程序员的惯例(应该说,这是所有程序员的惯例),凡是要一次次重新执行的命令,都应该写成脚本,变成“一个动作”。所以,简单来说,你会把上面这个命令序列写成一个build.sh,每次编译你只要执行这个脚本问题就解决了。
但这个脚本有问题,假设我修改了foo.c,但我没有修改bar.c和main.c,那么执行这个脚本是很浪费的,因为它会无条件也重新编译bar.c和main.c。
所以,这个脚本更合理的写法应该是这样的:
[ foo.o -ot foo.c ] && gcc -Wall -c foo.c -o foo.o
[ bar.o -ot bar.c ] && gcc -Wall -c bar.c -o bar.o
[ main.o -ot main.o] && gcc -Wall -c main.c -o main.o
[ app.executable -ot main.o ] && [ app.executable -ot foo.o ] && [ app.executable -ot bar.o ] && gcc main.o foo.o bar.o -lpthread -o app.executable这很复杂是不是?同样按Unix程序员的一般作风,如果你面对一个问题,不要尝试重新去定义这个问题,而是看它和原来的问题相比,多出来的问题是什么,尝试解决那个多出来的问题就好了。
那么这里,多出来的问题就是文件修改时间比较。这个就是Makefile要解决的基本问题了。我们定义一种新的“脚本语言”(只是不用sh/bash/tch来解释,而是用make来解释),可以用很简单的方法来说明我们需要做的文件比较。这样上面的脚本就可以写成这个样子了:
#sample1
foo.o: foo.c
gcc -Wall -c foo.c -o foo.o
bar.o: bar.c
gcc -Wall -c bar.c -o woo.o
main.o: main.c
gcc -Wall -c main.c -o main.o
app.executable: foo.o bar.o main.o
gcc main.o foo.o bar.o -lpthread -o app.executable这样读写起来是不是就简单多了?
这就是Makefile解决的原始问题。Makefile不是必须的,但它能减少你很多麻烦。有人可能会说,为什么要这么麻烦?我们用IDE就好了。IDE封装了Makefile的使用当然好,问题是IDE在里面都是用默认的规则(相当于有一个默认的Makefile),但如果你想具体控制特定文件的编译细节,最终你还不是一样面对这些问题? 所以,这个完全不是个IDE和make工具的对比问题,这两者解决的是问题的不同层次。
上面那个Makefile中,foo.o: foo.c定义了一个“依赖”,说明foo.o是靠foo.c编译成的,它后面缩进的那些命令,就是简单的shell脚本,称为规则(rule)。而Makefile的作用是定义一组依赖,当被依赖的文件比依赖的文件新,就执行规则。这样,前面的问题就解决了。
Makefile中的依赖定义构成了一个依赖链(树),比如上面这个Makefile中,app.executable依赖于main.o,main.o又依赖于main.c,所以,当你去满足app.executable(这个目标)的依赖的时候,它首先去检查main.o的依赖,直到找到依赖树的叶子节点(main.c),然后进行时间比较。这个判断过程由make工具来完成,所以,和一般的脚本不一样。Makefile的执行过程不是基于语句顺序的,而是基于依赖链的顺序的。
[phony依赖]
make命令执行的时候,后面跟一个“目标”(不带参数的话默认是第一个依赖的目标),然后以这个目标为根建立整个依赖树。依赖树的每个节点是一个文件,任何时候我们都可以通过比较每个依赖文件和被依赖文件的时间,以决定是否需要执行“规则”。
但有时,我们希望某个规则“总是”被执行。这时,很自然地,我们会定义一下“永远都不会被满足”的依赖。比如你可能会这样写:
test:
DEBUG=1 ./app.executabletest这个文件永远都不会被产生,所以,你只要执行这个依赖,rule是必然会被执行的。这种形式看起来很好用,但由于make工具默认认为你这是个文件,当它成为依赖链的一部分的时候,很容易造成各种误会和处理误差。
所以,简化起见,Makefile允许你显式地把一个依赖目标定义为“假的”(Phony):
.PHONY: test
test:
DEBUG=1 ./app.executable这样make工具就不用多想了,也不用检查test这个文件的时间了,反正test就是假的,如果有人依赖它,无条件执行就对了。
PHONY目标算不上是Makefile的基础知识的一部分,我之所以提出来,是要用一个简单的例子说明,“名称定义”是怎么影响“后续逻辑和新名称定义的”。所谓“为学日益”,就是这个意思,你为了解决一个问题,就会定义一个新的逻辑(名称),这个然后这个新的名称,就会制造新的问题,你解决那个问题,就需要新的名称定义,就会产生新的问题,就需要更多的名字。日益增加的“名字”,最终会成为对你脑子的DoS攻击,导致“控制”的最终失控。在这个例子中,因为我们引入了“目标和依赖”,所以我们才有了“假目标”这个定义,而因为我们有了“假目标”这个定义,我们后面就会引入“假依赖”的问题。你在整个逻辑思考的过程中,就不能不多考虑一个“名称要素”,这些是“成本”,要省着用。所以我们才有了“不敢为主而为客”。“为客”就是让每个“名称”都要“买下至少一个问题”,不解决问题的“名称”,就让它去死。
后面讨论的每个问题,我都隐含了这个逻辑,请读者从现在起就开始注意。
[宏]
前面的sample1明显还是有很多多余的成份,这些多余的成份可以简单通过引入“宏”定义来解决,比如上面的Makefile,我们把重复的东西都用宏来写,就成了这样了:
#sample2
CC=gcc -Wall -c
LD=gcc
foo.o: foo.c
$(CC) foo.c -o foo.o
bar.o: bar.c
$(CC) bar.c -o bar.o
main.o: main.c
$(CC) main.c -o main.o
app.executable: foo.o woo.o main.o
$(LD) main.o foo.o bar.o -o app.executable这个写出来,还是有“多余”的成份在,因为明明依赖中已经写了foo.o了,rule中还要再写一次,我们可以把依赖的对象定义为$@,被依赖的对象定义为$^(这是当前gnumake的设计),这样就可以进一步化简:
#sample3
CC=gcc -Wall -c
LD=gcc
foo.o: foo.c
$(CC) $^ -o $@
bar.o: bar.c
$(CC) $^ -o $@
main.o: main.c
$(CC) $^ -o $@
app.executable: foo.o woo.o main.o
$(LD) $^ -o $@很明显,这还是有重复,我们可以把重复的定义写成通配符:
#sample4
CC=gcc -Wall -c
LD=gcc
%.o: %.c
$(CC) $^ -o $@
foo.o: foo.c
woo.o: woo.c
main.o: main.c
app.executable: foo.o woo.o main.o
$(LD) $^ -o $@这终于短了吧。实际上,你要化简,还有很多手段,比如gnumake其实是默认定义了一组rule的,上面这个整个你都可以不写,就这样就可以了:
#sample5
LDLIBS=-lpthead
SRC=$(wildcard *.c)
OBJ=$(SRC:.c=.o)
app.executable: $(OBJ)这里其实没有定义.o到.c的依赖,但gnumake默认如果.c存在,.o就依赖对应的.c,而.o到.c的rule,是通过宏默认定义的。你只要修改CC,LDLIBS这类的宏,就能解决大部分问题了。所以你又省掉了一组定义,这就可以写得很短。
我前面的博文中说到,构架设计具有存在性的。这是一个例子,其实在我们开始定义最初Makefile的语义的时候,最后软件会长成这个样子,已经是可预期的了。这就叫执古之道,以御今之有。
[头文件问题]
现在我们把问题搞得复杂一点,增加三个头文件。比如foo.h, bar.h和common.h,前两者定义foo.c和bar.c的对外接口,给main.c使用,common.h定义所有文件都要用到的通用定义(foo.h和woo.h中包含common.h)。这样前面这个sample1就有毛病了。照理说,foo.h更新的时候,foo.o和main.o都需要重新编译,但根据那个定义,根本就没有这个比较。
为了增加这个比较,我们的定义必须写成这个样子:
#sample4+
CC=gcc -Wall -c
LD=gcc
%.o: %.c
$(CC) $< -o $@
foo.o: foo.c foo.h common.h
bar.o: bar.c bar.h common.h
main.o: main.c foo.h bar.h common.h
app.executable: foo.o bar.o main.o
$(LD) $^ -o $@(注:这个例子我们在.o.c依赖的规则中使用了$<宏,它和$^的区别是,它不包括依赖列表中的所有文件,而仅仅是列表中的第一个文件)
这就又增加了复杂度了——头文件包含关系一变化,我就得更新这个Makefile的定义。这带来了升级时的冗余工作。按我们前面考虑一样的策略,我们尝试在已有的名称空间上解决这个问题。Makefile已经可以定义依赖了,但我们不知道这个依赖本身。这个事情谁能解决?——把这个过程想一下——其实已经有人解决这个问题了,这个包含关系谁知道嘛?当然是编译器。编译器都已经用到那个头文件了,当然是它才知道这种包含关系是什么样的。比如gcc本身直接就提供了-M系列参数,可以自动帮你生成依赖关系。比如你执行gcc -MM foo.c就可以得到
foo.o: foo.c foo.h common.h这样,剩下的问题是Makefile得先生成依赖本身,然后再基于依赖来生成文件。这样,我们可以把Makefile写成这样(为了简单,我直接用sample5来改了):
#sample5+
LDLIBS=-lpthead
CFLAGS+=-MMD -MP
SRC=$(wildcard *.c)
OBJ=$(SRC:.c=.o)
DEP=$(SRC:.c=.d)
-include $(DEP)
app.executable: $(OBJ)CFLAGS中增加的参数可以为xxx.c产生xxx.d文件,里面就是那个依赖关系,然后我用-include包含这些依赖关系。这样就不再需要手工来写每个依赖了。为了解决这个问题,你已经看见了,include前面又增加了一个语法。那个减号表示允许被包含的文件不存在。
不仅如此,一旦引入这样的支持,我们就必须面对一个新的问题了:一开始foo.d不存在,Makefile所定义的依赖链是一个样子,等foo.d存在了,它又是一个样子。那make工具以哪个样子为准呢?
所以,这又引入了所谓的“remake rule”,决定了在什么时刻,make工具以什么为准。这个rule的细节,读者可以自己找手册看。大概的原理是make会第一次先认出所有的用于组成Makefile定义的文件,然后先make一次,等更新后,再做第二次的更新。名的复杂度,就是这样一步步建立起来的。“无中生有”的过程,在计算机软件领域其实表现得最为淋漓尽致。你说这个概念是本身就已经存在了,所以你定义出来了呢?还是因为你“发明”了它,所以它就存在了呢?
[autoconf]
然后我们接着处理下一个问题,因为我们有了Makefile,所以跨平台的问题就活该Makefile来解决了。跨平台要面对的是不同平台习惯不同的问题。这种问题一个解决方案是定义标准,比如POSIX。POSIX规定了,如果你要用malloc,你就应该包含stdlib.h。但你以为你是标准就是老大?我的平台就不包含stdlib.h,我就要包含alloc.h,怎么着?
你的编译器叫gcc,我的平台编译器就叫laozizuida_compiler,怎么着?
所以我们一开始会在Makefile前面包含一个文件,来生成这些定义,比如这样:
ifdef WINDOWS
include windows_def.mk
#endif
#ifdef LINUX
include linux_def.mk
#endif
...这样弄得编译的人非常头疼。如果我们比较一下,这个问题和Makefile鸟关系没有,它是个“自动化宏定义”的问题。autoconf,就是从这个角度解决这个问题的。它的工作是生成一组脚本,自动检查要参与编译的目标平台的某些定义应该是怎么样的,这样编译的人就不需要去做那么多复杂的定义了,运行一下自动编译脚本就好了。
所以,如果你拿到一份基于autoconf的源代码,它的编译方法是这样的:
./configure
make那个./configure取代了你手工设置参数过程,通过自动检查帮你设置参数。
autoconf相当于一个知识库,负责帮助你生成./configure。大部分gnu或者非gnu的开源项目都使用autoconf生成这个检查过程。如果你随便下载一个源代码,你会发现这个脚本写得相当复杂。为了生成这个复杂的脚本,autoconf为了你提供了一个更简单的语法——其实也不是什么简单语法了,它是通过m4这种宏语言,把你用宏写的脚本,变成这个configure文件。
用来生成configure的源文件叫configure.ac。这个东西的语法估计你也很难学。一般情况下,其实你也不用学。autoconf提供了一个工具,叫autoscan,它可以根据你的源代码,自动帮你生成一个模板,比如,在我这个空的只有foo,bar,main的工程中,它生成的模板就是这样的:
# -*- Autoconf -*-
# Process this file with autoconf to produce a configure script.
AC_PREREQ([2.69])
AC_INIT([FULL-PACKAGE-NAME], [VERSION], [BUG-REPORT-ADDRESS])
AC_CONFIG_SRCDIR([bar.c])
AC_CONFIG_HEADERS([config.h])
# Checks for programs.
AC_PROG_CC
# Checks for libraries.
# Checks for header files.
# Checks for typedefs, structures, and compiler characteristics.
# Checks for library functions.
AC_FUNC_MALLOC
AC_CONFIG_FILES(Makefile)
AC_OUTPUT这个语法都不怎么需要学,对着改就是了,前后的两段宏是用来生成configure的开头和结尾的,不要动,中间就放一堆的检查,检查结果会生成一组Makefile可以用的宏定义。
其中AC_CONFIG_SRCDIR是用来确定脚本是不是放在正确的源代码目录中的,所以输入参数是其中一个“肯定会有”的源程序即可。
AC_CONFIG_FILES用来定义进行宏转换的文件,脚本生成了一堆宏以后,会读入这里定义的文件,然后把其中的宏都替换掉。比如这里的参数是Makefile,脚本会找目录中的http://Makefile.in,然后把里面的宏替换掉,生成Makefile。剩下的事情会怎么样,猜都猜到了。
剩下的就是中间那些检查函数了,比如AC_PROG_CC用来检查gcc的名字,AC_FUNC_MALLOC用来检查malloc函数是否被支持,一般来说也不用学,因为autoscan会自动根据你的源代码找出来的。
把这个模板保存为configure.ac文件,然后执行autoconf,就会生成configure脚本,这样你就不用关心更多的跨平台的细节了。如果你修改过源代码,觉得自己调用了更多的库。可以重新运行autoscan,把新的,你觉得有用的检查也补充进去就可以了。
把上面这个过程画成一副图,就是这个样子的:
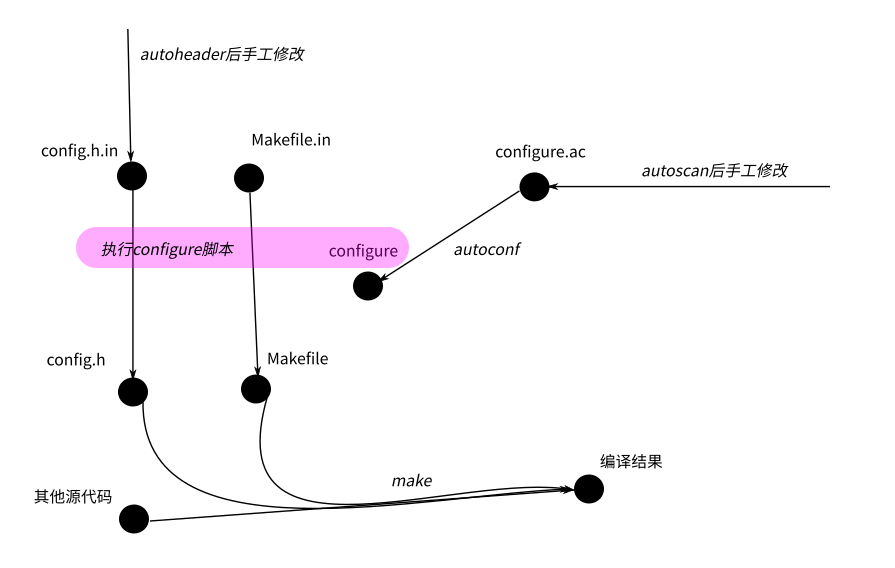
也许你已经注意到了,图中比我的描述多了http://config.h.in,这只是另一个类似autoscan的helper工具,辅助你生成不同平台上不同库函数宏定义的,你自己运行一下autoheader就明白了。
我们说了,configure.ac其实是基于autoconf预定义的宏写的一个脚本,所以,你在里面直接写脚本一点问题没有,比如,我有时会这样插一段进去:
...
AC_CHECK_LIB([ossp-uuid], [uuid_create], [OSSPUUIDLIB="-lossp-uuid"])
if test "x$OSSPUUIDLIB" = "x"; then
AC_CHECK_LIB([uuid], [uuid_create], [UUIDLIB="-luuid"])
fi
if test "x$OSSPUUIDLIB$UUIDLIB" = "x"; then
AC_ERROR([No uuid library available])
fi
LIBS="$LIBS $UUIDLIB $OSSPUUIDLIB"
...AC_CHECK_LIB是autoconf的m4宏,它负责检查ossp-uuid这个库是否存在,如果它不存在,我可以用uuid,如果两个都不存在,我就报错。我需要的仅仅是autoconf的检查功能,其他东西要怎么弄,完全在我的掌控之下。
所以,这个用起来自由度其实是很高的,你会写脚本就可以了。autoconf只是个知识库,提醒你要主要跨平台的时候有什么要考虑的。你要自己增加什么检查,那是你的事情。整个脚本体系可以一步步完善的。要知道你的检查产生了哪些宏,运行一次configure,然后检查一下config.log就可以了,你会看到类似这样的东西:
## ----------------- ##
## Output variables. ##
## ----------------- ##
ACLOCAL='${SHELL} /home/kenny/work/hisi-repo/kernel-dev/samples/wrapdrive/missing aclocal-1.15'
AMDEPBACKSLASH='\'
AMDEP_FALSE='#'
AMDEP_TRUE=''
AMTAR='$${TAR-tar}'
AM_BACKSLASH='\'
AM_DEFAULT_V='$(AM_DEFAULT_VERBOSITY)'
AM_DEFAULT_VERBOSITY='1'
AM_V='$(V)'
AR='ar'
AUTOCONF='${SHELL} /home/kenny/work/hisi-repo/kernel-dev/samples/wrapdrive/missing autoconf'
AUTOHEADER='${SHELL} /home/kenny/work/hisi-repo/kernel-dev/samples/wrapdrive/missing autoheader'
AUTOMAKE='${SHELL} /home/kenny/work/hisi-repo/kernel-dev/samples/wrapdrive/missing automake-1.15'
AWK='gawk'
CC='gcc'
CCDEPMODE='depmode=gcc3'
CFLAGS='-g -O2'
CPP='gcc -E'
CPPFLAGS=''
CYGPATH_W='echo'
DEFS='-DHAVE_CONFIG_H'
DEPDIR='.deps'
DLLTOOL='false'
DSYMUTIL=''
DUMPBIN=''
ECHO_C=''
ECHO_N='-n'
ECHO_T=''
EGREP='/bin/grep -E'
EXEEXT=''
FGREP='/bin/grep -F'
GREP='/bin/grep'
INSTALL_DATA='${INSTALL} -m 644'
INSTALL_PROGRAM='${INSTALL}'
INSTALL_SCRIPT='${INSTALL}'
INSTALL_STRIP_PROGRAM='$(install_sh) -c -s'
LD='/usr/bin/ld -m elf_x86_64'
LDFLAGS=''
LIBOBJS=''
LIBS='-luuid -lsysfs -lpthread '
LIBTOOL='$(SHELL) $(top_builddir)/libtool'
LIPO=''
LN_S='ln -s'
LTLIBOBJS=''
LT_SYS_LIBRARY_PATH=''该怎么用,也不用我说了。
我经常说,“也不用我说了”。这也是一种架构师习惯:但凡只剩下工作量的事情,就不再考虑,无论这个事情以后是我自己干还是让别人干。至少构架方面的工作是做完了。所谓架构设计,就是设计到怎么演进也不会有什么大风浪了为止。(但什么程度才不会有大风浪,取决于为你工作的工程师是什么水平和习惯)
[automake]
有了autoconf,检查工作简单多了,但http://Makefile.in还是不好写。所以,我们又有了automake,用来产生http://Makefile.in。
automake用http://Makefile.am作为输入,生成http://Makefile.in。它提供了一个非常简单的语法,类似这样的:
lib_LTLIBRARIES=libfoo.la
libwd_la_SOURCES=foo.c bar.c common.h foo.h bar.h
bin_PROGRAMS=app
app_SOURCES=main.c
app_LDADD=.libs/libfoo.a这个很简单吧:你要编译一个二进制,就把名字赋给bin_PROGRAMS,然后描述它的源代码是什么,剩下的事情全部交给automake。
automake依赖autoconf,所以对configure.ac的写法有一些额外的要求。我这里是介绍原理,不是介绍细节,所以这个读者随便搜索一下就能找到大把材料,简单试用一下就知道怎么弄了。
我这里更愿意讨论这样一个问题:语义其实就是这么一回事——你要简单,你就失去细节的控制,你要深入控制,你就要面对复杂度。所以,很大程度上,我们进行抽象,都是在两者之间取得平衡,并没有“完美”的方法。你脑子里想得特好的“美好生活”,到你亲自去体验的时候,你又觉得非常Boring。你的意愿,和你的好恶,并不重合。
所以,我们进行抽象设计,本质上是判断什么是使用者“不在乎”的部分,把那部分帮他选了。你的模块就产生对他的价值。所以,Unix这种插件、组合式的设计是有道理的。你什么都帮用户做了,总有他不满意的部分,每个都可以成为他把你整体放弃的理由。而分离的插件,则是一个个独立的“逻辑收缩”,你要收缩哪部分逻辑(不想管细节),就单独用那一个“逻辑收缩”就好了。至于更大规模的收缩,我们可以通过小逻辑组合出来。好比这个automake,如果你仅仅就是编译一个Unix上的应用程序,该有的都有了,但如果你要控制一堆自动生成的代码,它就不够看了,但这不影响你放弃automake,继续使用autoconf和makefile等的功能。
所以评论中有人问,为什么有cmake这么高级的工具,还需要学习Makefile。这就看你到底要控制到什么层次了。
[关于架构的进一步讨论]
Makefile相关的概念我介绍完了,我觉得大线条我描述完了,细节可以看工具手册本身,但如果读者觉得在大线条上哪里有不理解的,请提问,我再补充。
现在回到我想讨论的构架设计的问题上。
写程序是个精细控制的过程,至少现在如此。我们大部分程序员习惯了c=a+b,e=c+d这样一步步逻辑组合的过程。很容易忘掉,构架是个粗糙控制的过程,构架的说法常常只是“算一下这个多边形的面积”这种类型的。这听起来好像是种“老板要求”,在程序员看来是“技术白痴”的要求。而架构师和两者的区别在于,架构师需要满足老板(客户)的意欲,同时保证它是可行的。
所以架构师的思路(注:架构师也可以是程序员,当他进行架构设计的时候,我们认为他是架构师。我一直都在写代码,但我进行架构设计的时候,干的活和我写代码的时候干的活是完全不同的)和程序的思路是很不同的。这就好像你画一副画,打架子的时候和你细绘眼睛的时候是完全不同的。
架构师在打架子的时候,考量的是,一旦这个架子定义成这样了,我把钱洒到这个架子中,它最后会长什么模样。
软件首先是个工程问题,构架只是解决它“有机会成型”的问题,但工程上,你能否在每个阶段都让你的软件保持一定的“收益”,这才是它最后“能成型”的关键。而保持这种收益的关键就在于每波投资,都能产生“收益”,我们抛开商业收益这么远的东西,首先要解决一批人的问题吧。在我们介绍Makefile这套工具的过程中,我们看到了这种变化的过程:
一开始你仅仅解决“更简单地描述文件依赖”这个问题,然后你简化用户描述的过程,然后你加入自动平台判断,然后你加入“最简化描述Unix文件生成方法”……这每一次扩展,都是在迎合一波足够Solid的用户需要,然后才前进的。构架控制的整个过程,就好像冲浪,不是你有多用力去滑水去让滑浪板前进。而是你必须准备好,迎接下一个浪尖,浮起来,然后顺势滑下去的一个过程。
能让一个架构生存下去,是因为这样的需求压力,而不是“投资”,“投资”会导致你有钱,有钱就会任性,任性就会把钱投资在没有需求backup的功能上,比如说,假设这个automake拿到一个亿的投资,他们可以把这个功能做出花来,界面支持,用AI进行辅助脚本生成,等等等等。但为此也就解决一个生成http://Makefile.in,能持续养活这些人吗?
[总结]
总的来说,我想说的是,
第一,架构设计是存在的。前提是你注意到它,如果你进行增量设计的时候,从来都是推翻前面的概念空间来从新开始,当然注意不到它的存在
第二,架构设计的架子和架构维护的过程,是完全不同的两个思路。前者保证的是生存的可能性,后者是积累每一波的能力,浇灌到架子中,让它长起来。
所以,控制架构的过程,不是控制软件如你所愿的过程,而是一个捕获“现实世界如何”的一个过程。